

RPAを使ってWebスクレイピング
 かじむー
かじむー
RPAの動きを実際に見てみよう!
いきなりですが!
PowerAutomateDesktopで作ったロボットが
どんな風にスクレイピングするか動きを見てみましょう!
PowerAutomateDesktopで作った中身を解説
中身はPythonで作ったものを
そのままPowerAtuomateDesktopの機能で置き換えただけですね!
ポイントを絞って簡単に解説します!
「変数の設定」から
商品名・価格・特性・会社名 を
格納するテーブルを作ります!
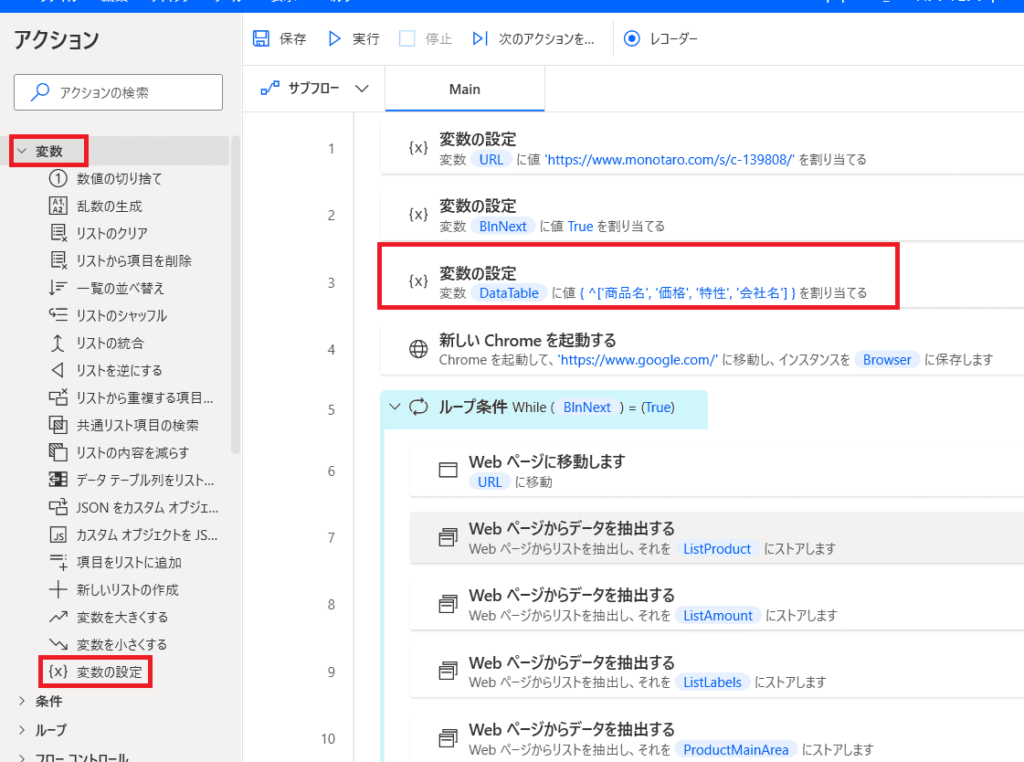
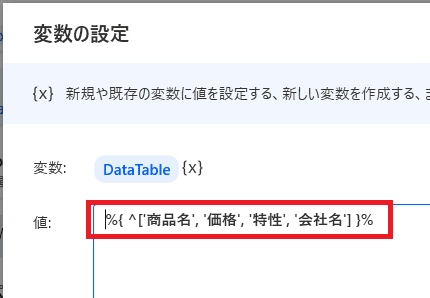
%{ ^['商品名', '価格', '特性', '会社名'] }%と書いてあげると
列だけ先に出来上がります!
上記の記事を参考にさせて頂いてます!感謝です_(._.)_
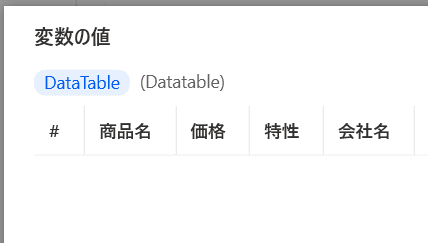
そしてこのテーブルに
スクレイピングした情報を追加していきましよう!
まずはChromeを立ち上げる!
「ブラウザ自動化」→「新しいChromeを起動する」
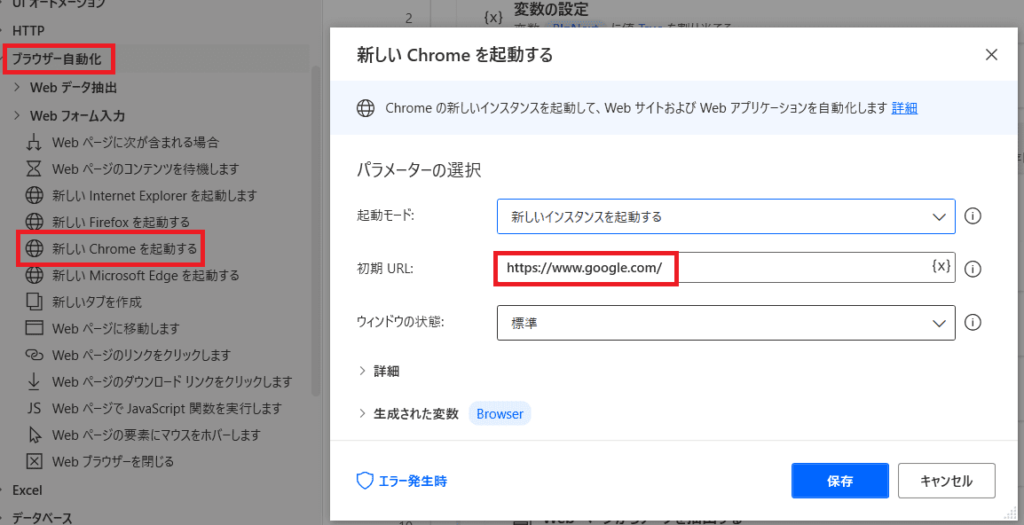
この初期URLに
遷移先のURLを直接入力してもいいし
Chrome起動後の処理に
「ブラウザ自動化」→「Webページに移動します」を追加し
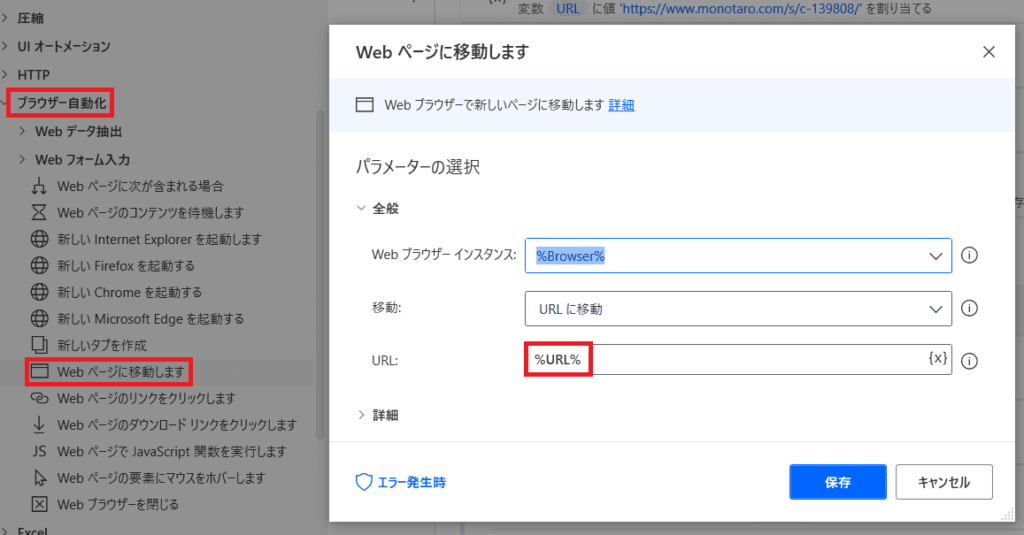
ここでURLに
遷移先URLを入力してもいいですね!
次にWebページ上の
品名や価格などをスクレピングします!
「ブラウザー自動化」→「Webデータ抽出」→「Webページからデータを抽出する」
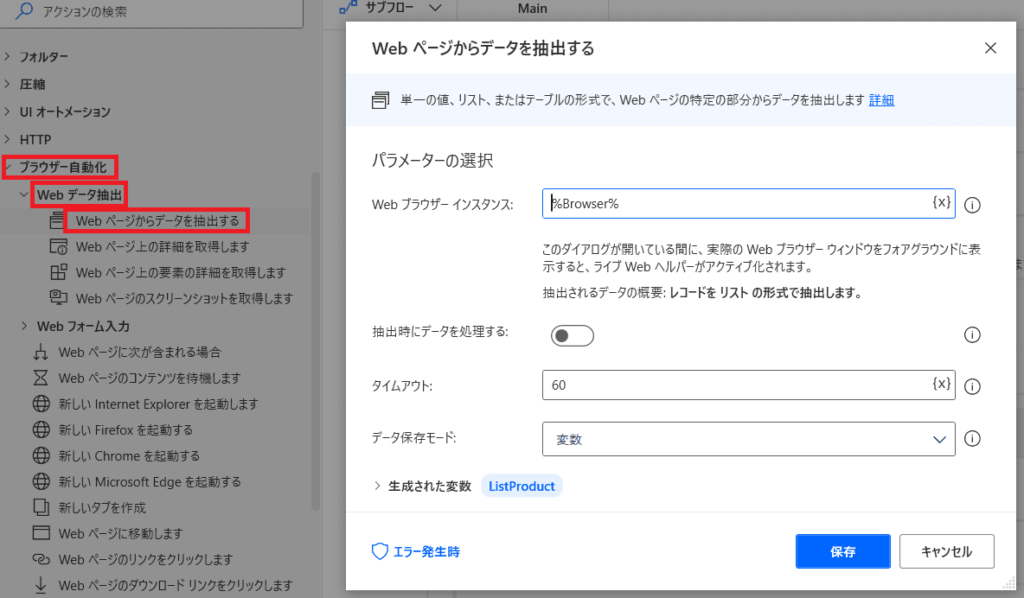
次にスクレイピングしたいWebページを開きます!
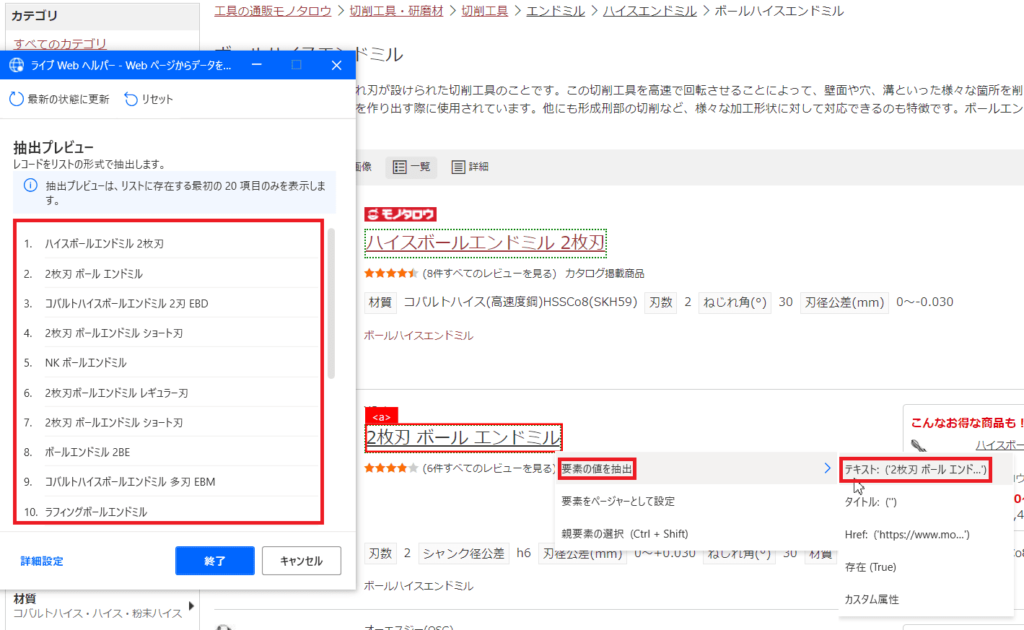
画面上をマウスで触れると
自動的に要素単位で赤枠が出てきます!
スクレイピングしたい部分で
右クリックして「要素の値を抽出」→「テキスト」
とするとテキスト値を取得できます!
実際の様子が見たい人は
動画をご覧ください!
もっと詳しい解説が欲しい方は
下記記事もご覧ください!
初めに作っておいた箱に
スクレイピングデータを追加します!
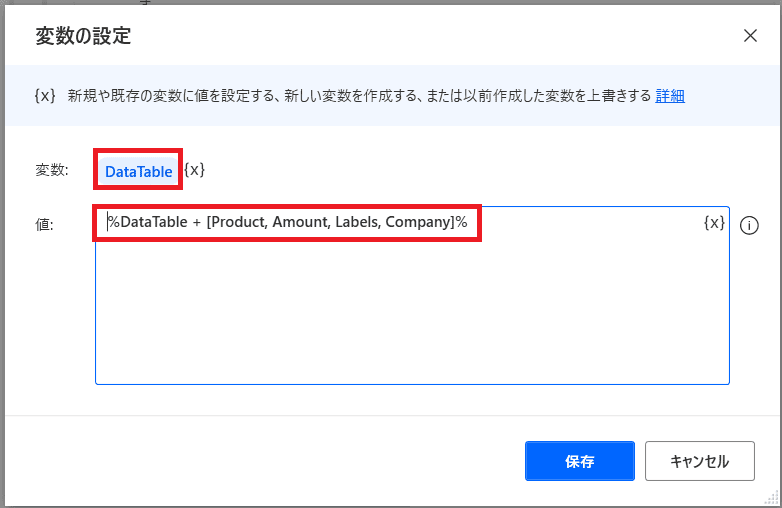
%DataTable + [Product, Amount, Labels, Company]%繰り返し処理の中で
情報を1つずつテーブルに追加する場合とかに使えますね!
[ 情報①, 情報②, 情報③, 情報④ ]と書くことで
1行分のデータとしてテーブルに追加できます!
全ての情報をテーブルに追加したら
Excelに出力したりして見える形で出してあげましょう!
1ページだけでなく
「次のページ」が存在する場合もありますよね!
その場合は
「次のページ」の要素を取得して判断しましょう!
「ブラウザー自動化」→「Webデータ抽出」→「Webページ上の要素の詳細を取得します」
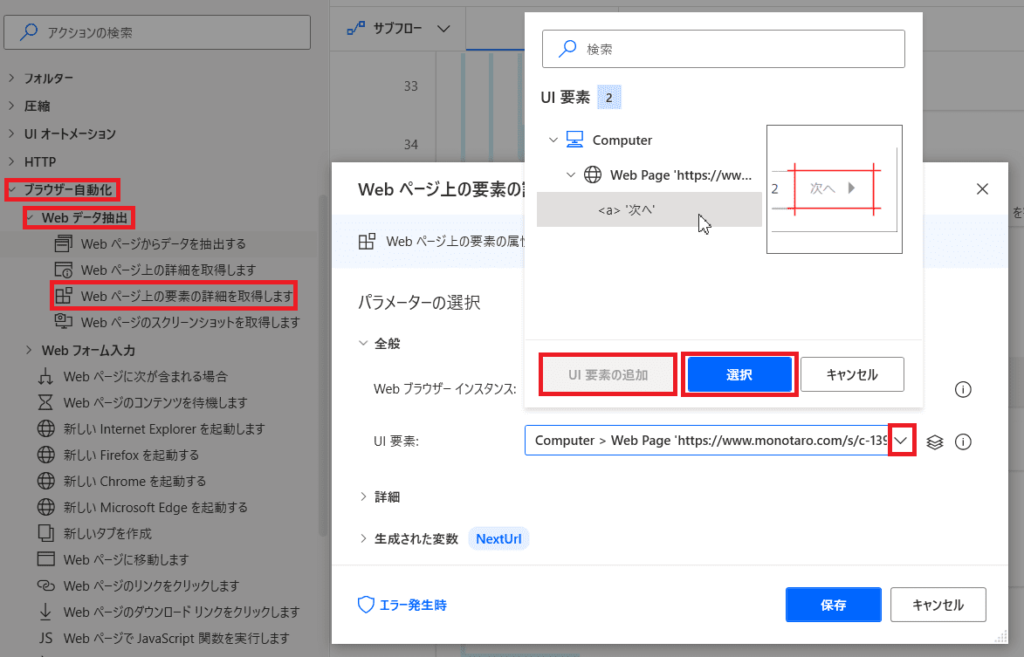
「▽」から「UI要素の追加」をした後
ページ上の「次へ」の要素を選択すると
その要素の詳細を取得できます!
あとは詳細からHrefを選択すれば
次のページのURLを取得できますね!
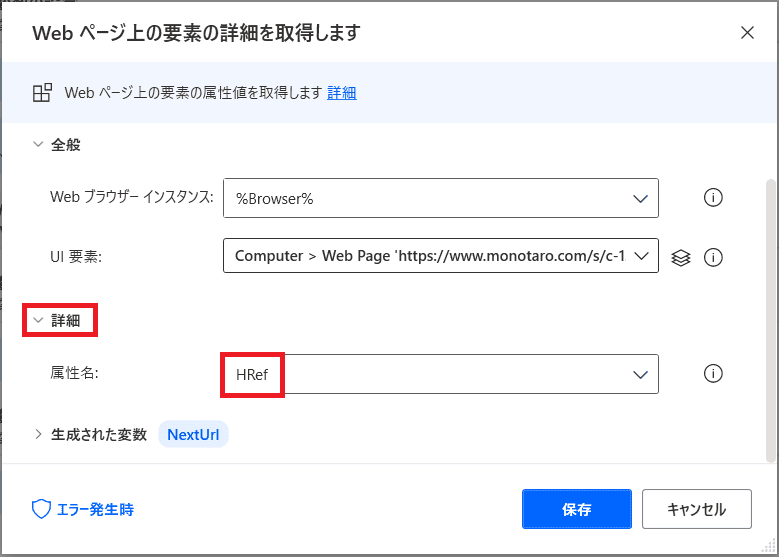
こうする事でページ数が多くても
次のページに遷移して同じ処理を行えますね!
かじむー

