

Pythonを使ってWebスクレイピング
 かじむー
かじむー
スクレイピング対象のページ
今回は工具通販サイトの「モノタロウ」さんから
商品情報を収集します!
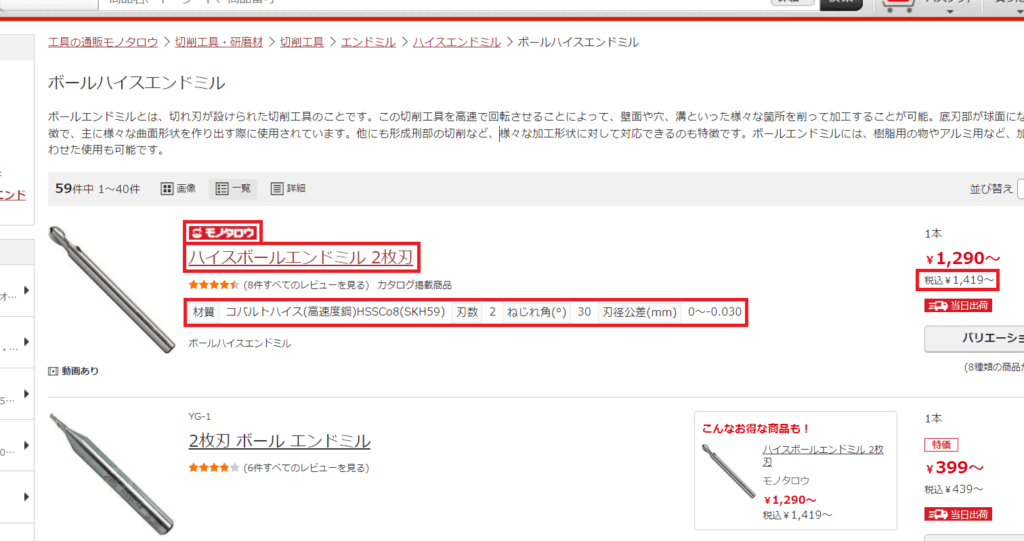
商品は「ボールエンドミル」に絞って
①ブランド:モノタロウ
②品名:ハイスボールエンドミル 2枚刃
③特性:材質コバルトハイス(高速度鋼)HSSCo8(SKH59)|刃数2
④価格税込:¥1,419~
を全ページ取得してみます!
スクレイピングで便利なSelenium
今回はWebページ上の動的な部分も対象なので
実際にブラウザを操作できるSeleniumを使います!
以前の記事で
VB.NETにてSeleniumを使った記事を公開しました!
 【VB.NET】Chromeを操作してファイルダウンロードを自動化してみた
【VB.NET】Chromeを操作してファイルダウンロードを自動化してみた
ブラウザのバージョンに
WebDriverのバージョンをそろえる必要があったため
手動でWedDriverを更新していました!
しかし!
自動でWebDriverを更新してくれる
ライブラリが出ていました!
公式(GitHub):webdriver_manager
これを使ってPythonを実装してみます!
サンプルコード
まずはライブラリをインストールします!
pip install webdriver-managerChromeを操作したいので
ChromeのWebドライバーを準備します!
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)optionに3つ設定して
WebDriverを準備しました!
options = webdriver.ChromeOptions()options.add_argument('--headless')options.add_experimental_option('excludeSwitches', ['enable-logging'])「システムに接続されたデバイスが機能していません。 (0x1F)」
というエラーコメントが出てくるので
③は↓の記事を参考にさせて頂きました!
url: str = "https://www.monotaro.com/s/c-139808/"
driver.get(url)こんな感じでurlの画面に遷移します!
例えばモノタロウさんの
ページ上の商品一覧を全て取得する場合!

Class名 が SearchResultProductColumn の要素を全て取得する!
from selenium.webdriver.common.by import By
data_elm = driver.find_elements(By.CLASS_NAME, 'SearchResultProductColumn')また、例えばモノタロウさんの
ページ上の「次へ」のURLを取得する場合!
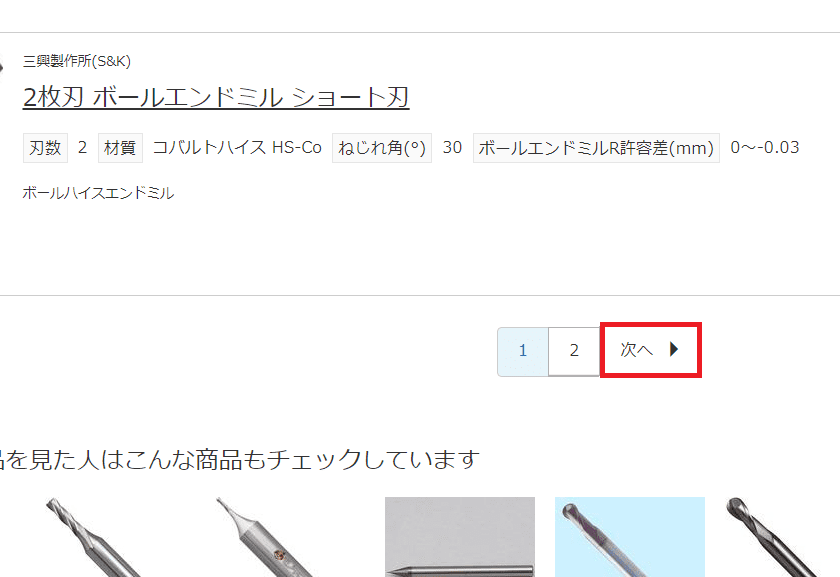
Class名 が Pagination の要素の中に在る
aタグの中から
テキスト値が「次へ」の href 値を取得する!
next_elm = driver.find_element(By.CLASS_NAME, 'Pagination')
a_next_elm = next_elm.find_elements(By.TAG_NAME, 'a')
a_next_url: list = [a.get_attribute('href') for a in a_next_elm if a.text == "次へ"]こんな感じで
全てのページの商品情報を取得できます!
サンプルですが
こんな感じでSeleniumを使って
商品情報を取得できます!
10ページ以上はスクレイピングしない作りになってます!
実際に動く様子が見たい方は
こちらの動画をご覧ください!
プログラムなんて書けません!
そんな方もいらっしゃると思います!
そうです。
もうプログラムを書く時代は終わりました
書けない人は
プログラミング不要のRPAを使って
Web情報を収集してみましょう!
気になる方は次のページ!

