

画像の中にある文字を目で確認して
手入力している事ってないでしょうか?
注文書や伝票など
情報を目で見て転記していると
ミスも起きやすく、時間もかかりますよね!
今回はそれを解決するために
RPAソフト、PowerAutomateDesktopを使って
全てを自動化していきたいと思います!

OCR機能を使って画像から文字を抽出
OCRとは?
と難しく感じる方もいると思いますが
それを可能にしてくれる機能があります!
それがOCRです!日本語では光学文字認識と言います!
光学文字認識(こうがくもじにんしき、英: Optical character recognition)は、活字、手書きテキストの画像を文字コードの列に変換するソフトウェアである。画像はイメージスキャナーや写真で取り込まれた文書、風景写真(風景内の看板の文字など)、画像内の字幕(テレビ放送画像内など)が使われる[1]。一般にOCRと略記される。
引用:Wikipedia
という感じで
画像内の文字を抜き出してくれる技術!凄いですよね!
そしてPowerAutomateDesctopには
この機能が備わっています!
では使って見ましょう!
画像内の全ての文字を抽出してみよう
 かじむー
かじむー
【1】OCRを使ってテキストを抽出

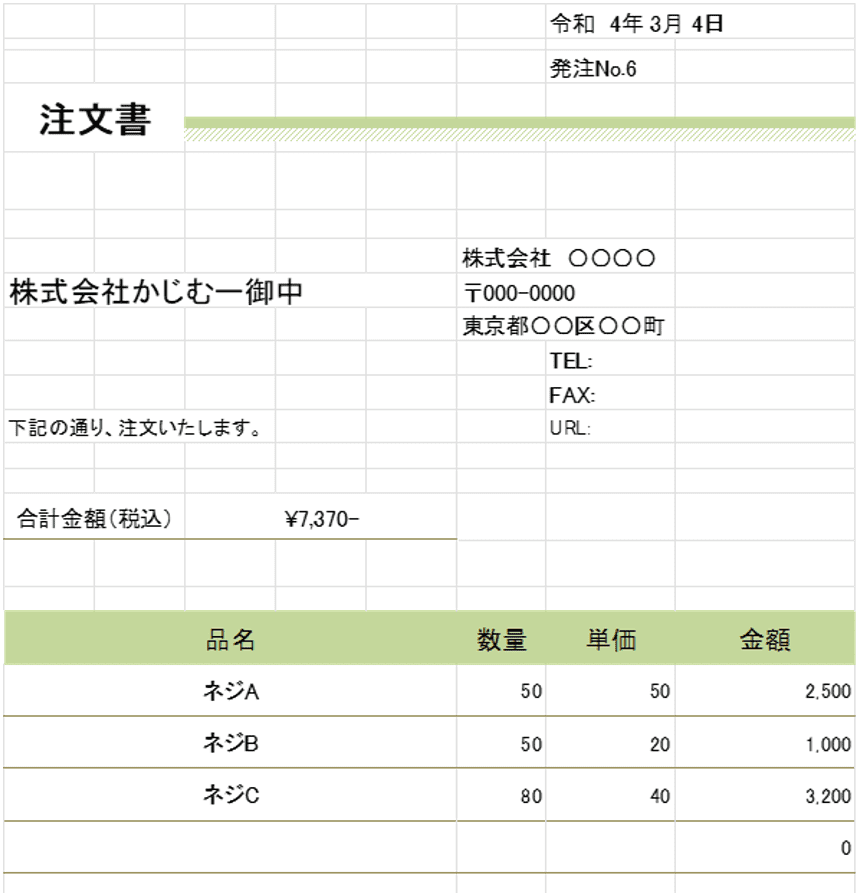
機能欄から「OCRを使ってテキスト抽出」を選択
■OCRエンジンの種類:WindowsOCRエンジンで良いでしょう!
■OCRソース:PCに保存した画像を選びたいのでディスク上の画像!
■画像ファイルパス:ここで画像を選びましょう!
■画像の幅・高さの乗数:ここは文字がきちんと読み取れるような数に調整していきましょう!
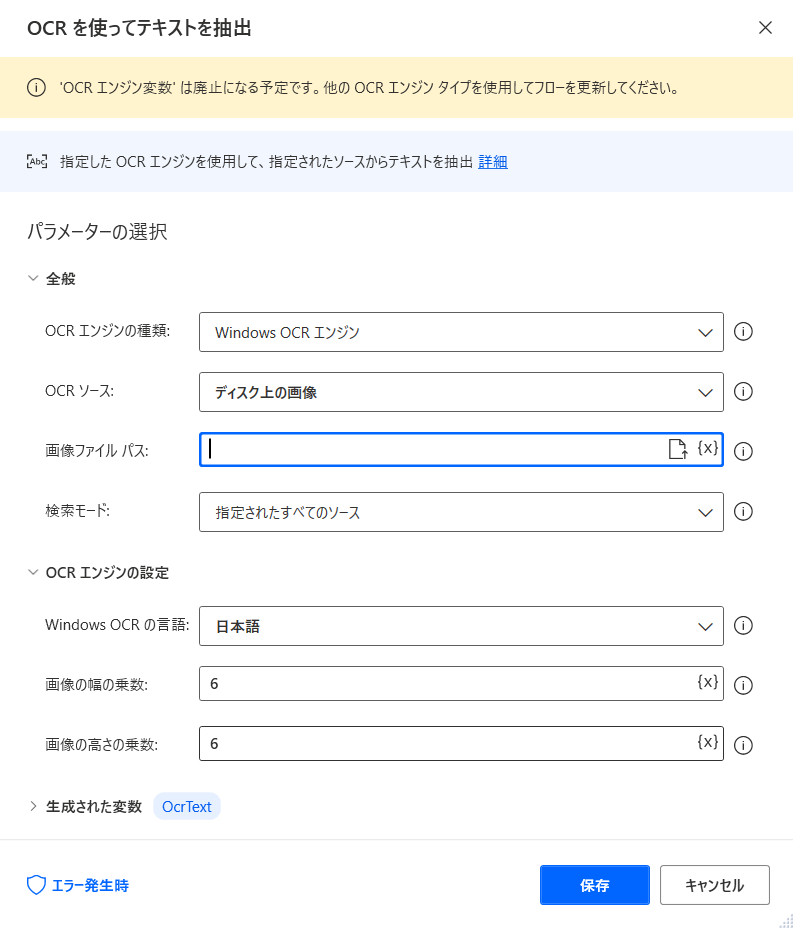
【2】メッセージボックスで抽出内容を確認
「メッセージボックス」の「メッセージを表示」を選ぶ!
「表示するメッセージ」には
先ほどOCRで抜出した文字が格納されている変数「OcrText」を選ぶ!
これで実行してみると…

成功してますね★
特定の箇所のテキストだけを抽出
かじむー
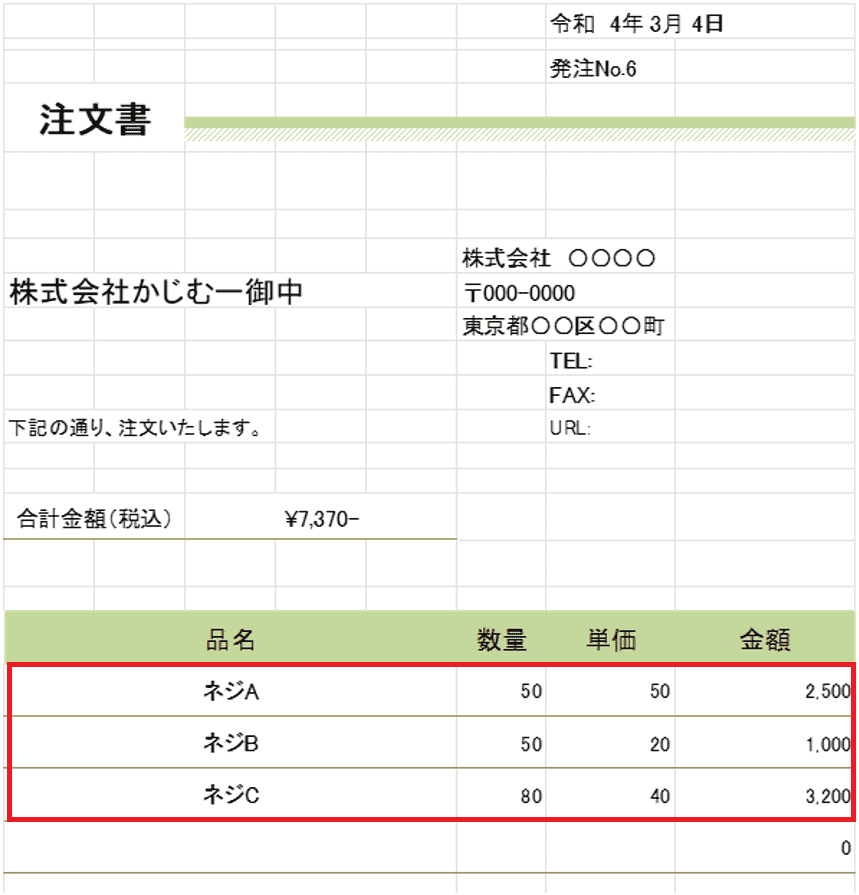
抽出したいテキストの位置を確認
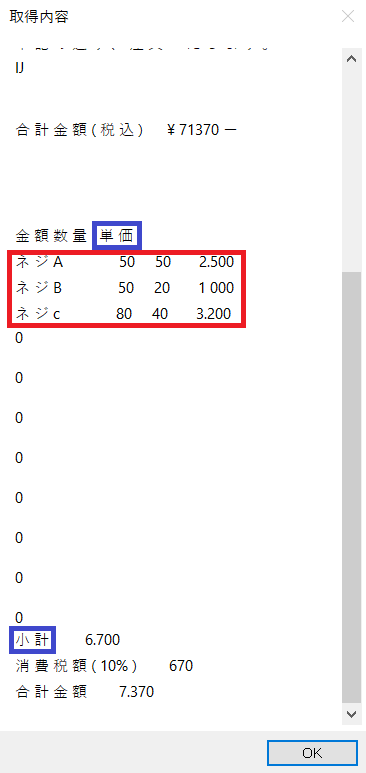
赤枠部分のテキストだけを抜き出したい!
このテキストはどんな文字に挟まれているか?
見てみると・・・
「単 価」と「小 計」に挟まれている!
※「0」はテキスト内に沢山存在するので避けて考えております
テキストの解析
【1】抽出したい文字の開始位置を特定
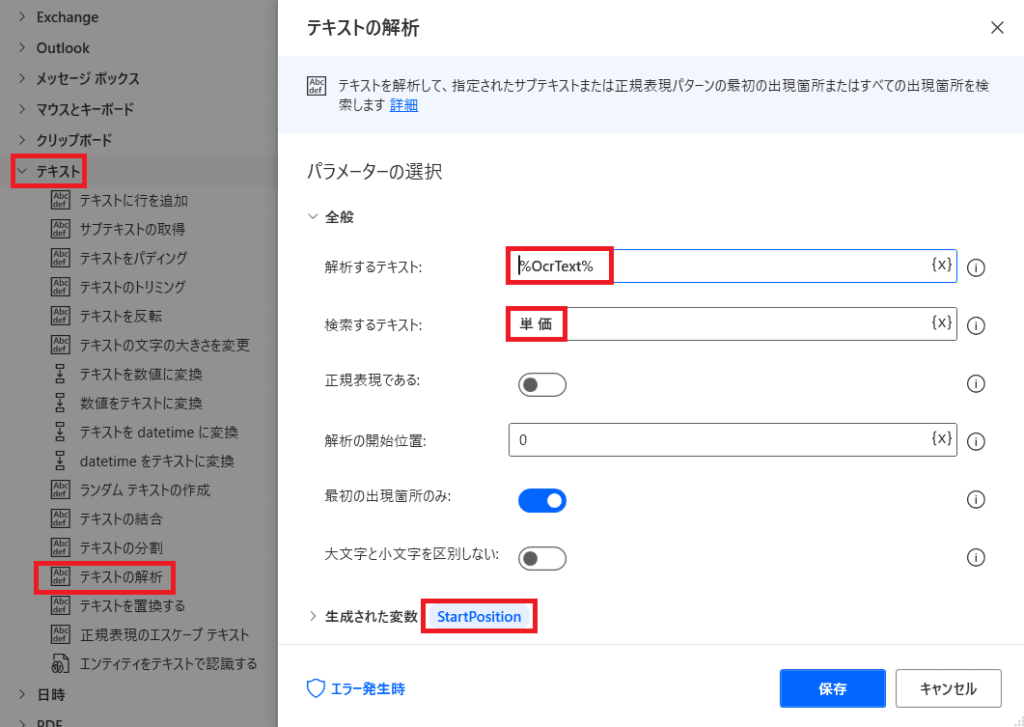
「テキスト」から「テキストの解析」を選ぶ!
そして画像の様に値をセットしていくと
画像から抜き出した文字列に対して
「単 価」が何文字目にあるか?という数値が
「StartPosition」という変数に格納されます!
【2】抽出したい文字の終了位置を特定
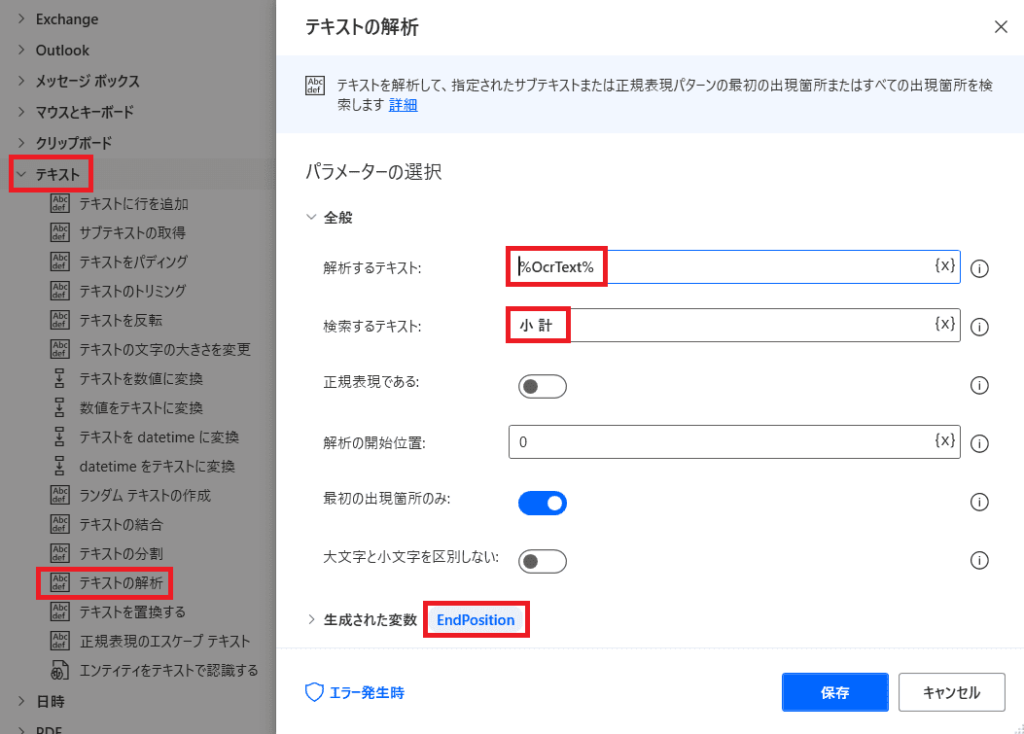
「テキスト」から「テキストの解析」を選ぶ!
そして画像の様に値をセットしていくと
画像から抜き出した文字列に対して
「小 計」が何文字目にあるか?という数値が
「EndPosition」という変数に格納されます!
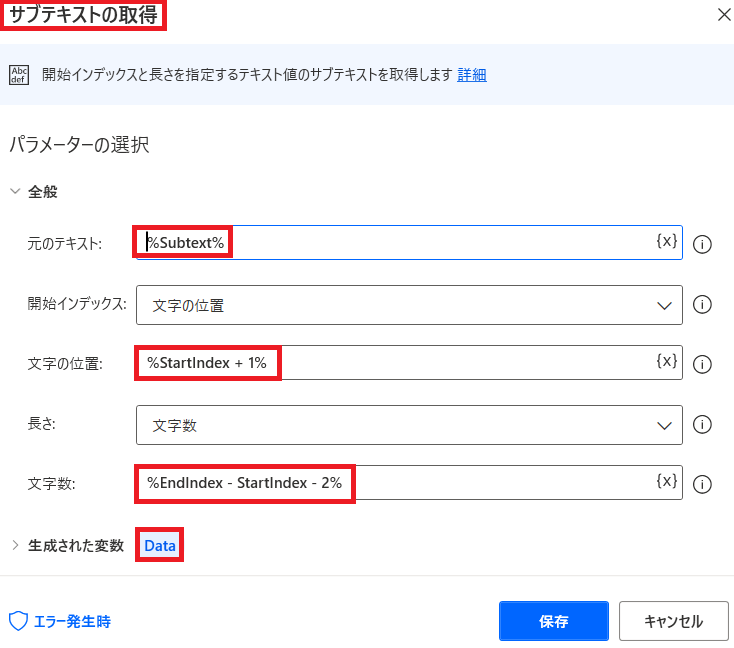
【3】サブテキストの取得
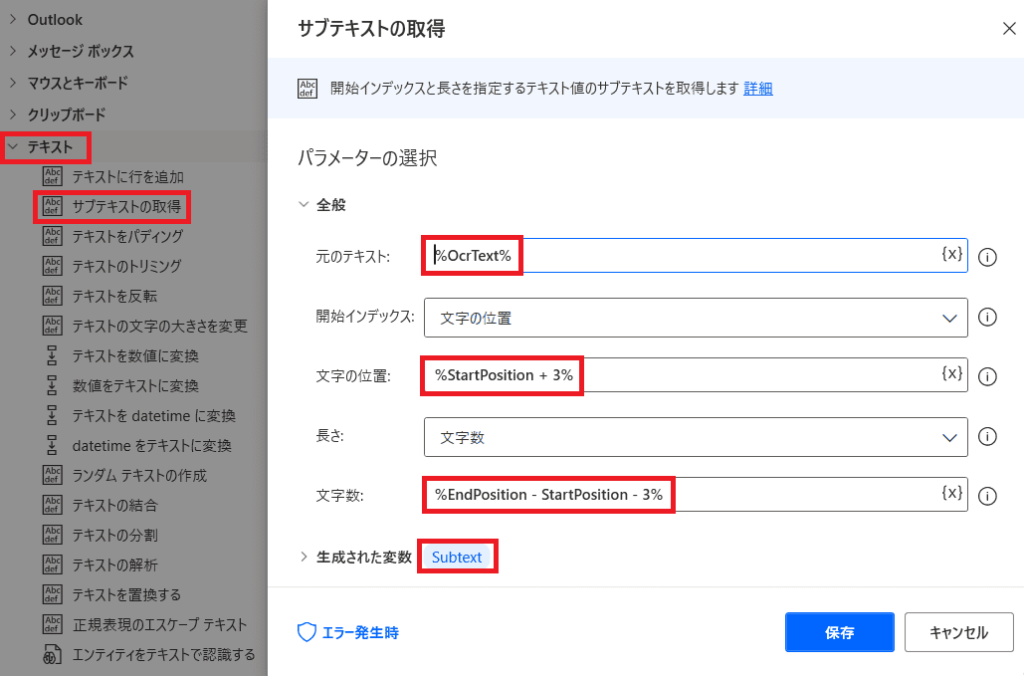
これで抜出す開始位置と終了位置が特定できたので
「テキスト」から「サブテキストの取得」を選ぶ!
そして画像の様に値をセットしていく!
「+3」「-3」と言うのは
抜出す部分から「単 価」「小 計」自身を除くための調整です!
そうすると
抜出した文字が「Subtext」という変数に格納されます!
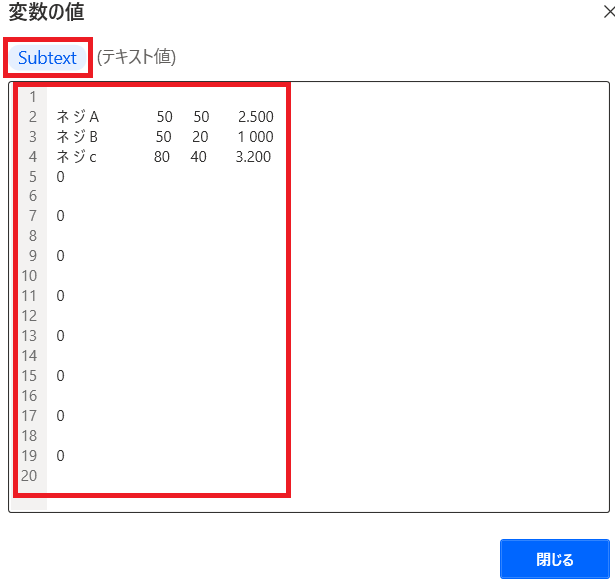
抽出したテキストをテーブル化
かじむー
テーブルの列名を作成
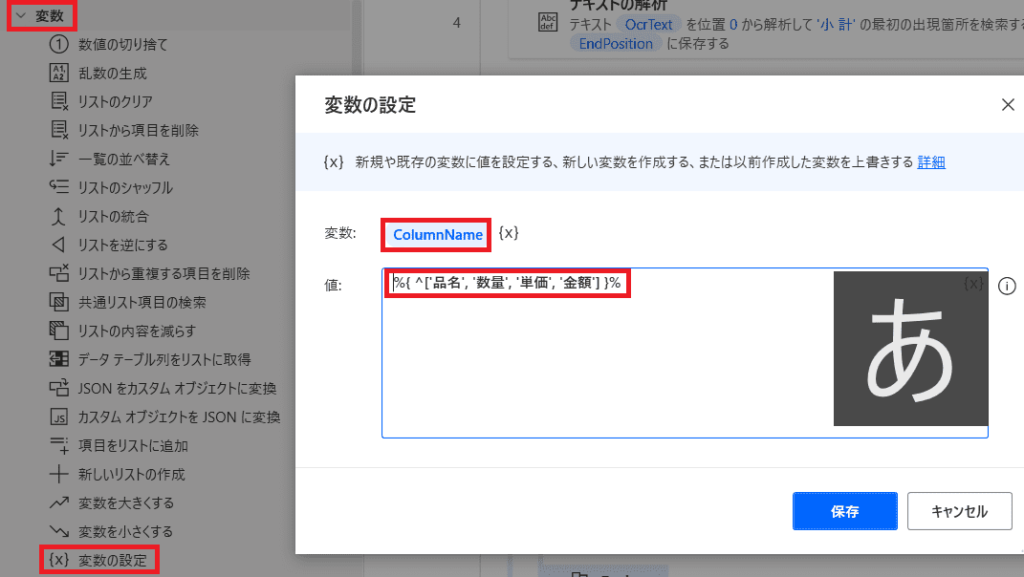
変数の設定から
変数名をColumnNameとし、値を、
%{ ^['品名', '数量', '単価', '金額'] }%
こうする事で↑こんな感じに
テーブルの列名だけが完成します!
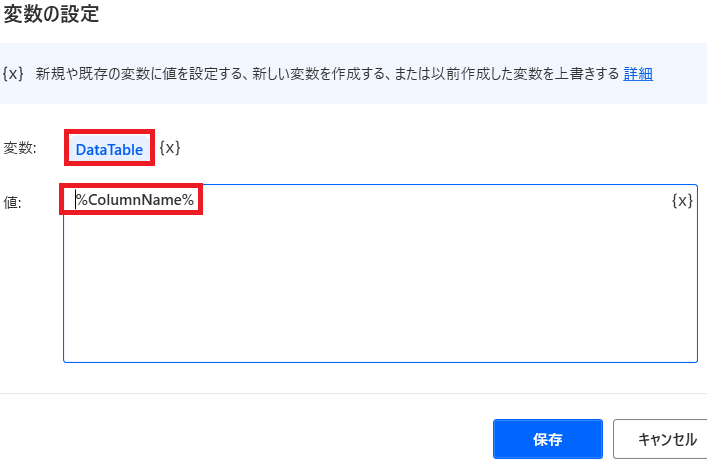
データ追加用に「DataTable」という変数を作り
このテーブルの列名にColumnNameをセットしておきます!
テキストを1行ずつ読込む準備
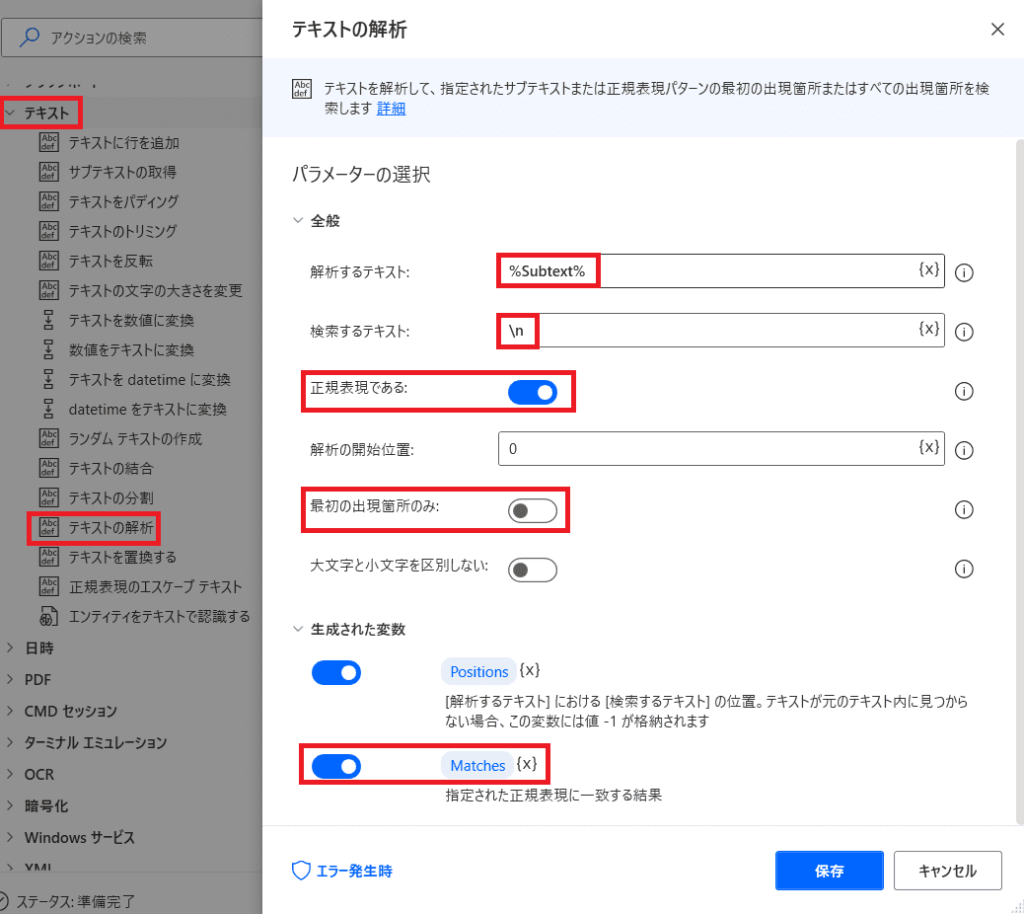
1行ずつ読込むために
改行の位置を全て特定します!
「テキスト」の「テキスト解析」を選ぶ!
そして画像の様に値をセットしていく!
「改行」は正規表現「\n」で検索します!
そして「最初の出現箇所のみ」のチェックを外すことで
すべての改行位置を特定し
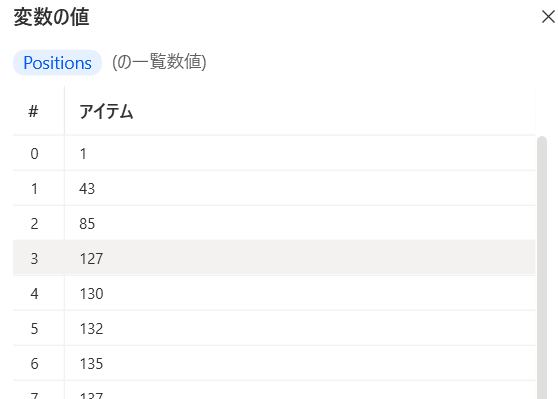
「Positions」変数に格納されます!
テキストを1行ずつ読込み、必要なデータをテーブルに追加
【1】繰り返し処理をセット
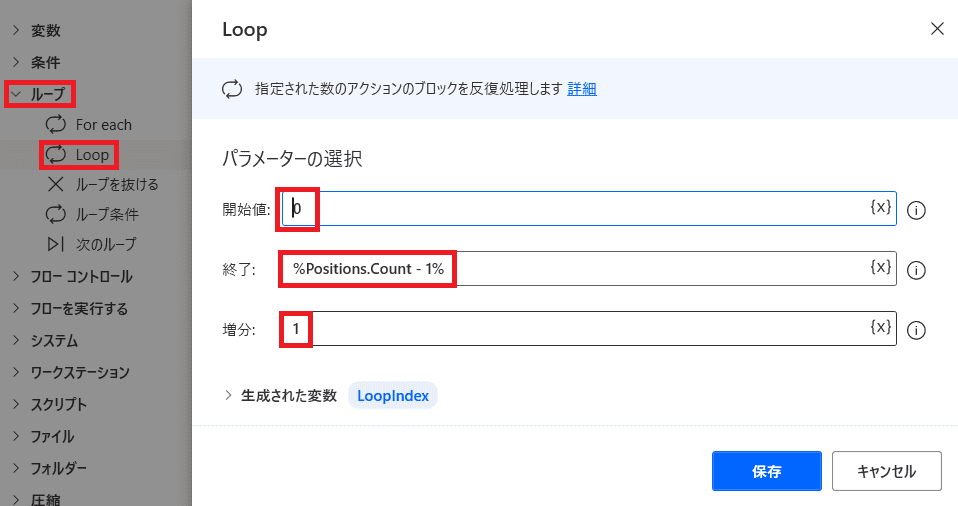
「ループ」から「Loop」を選ぶ!
画像の様に値をセットすると
0からスタートして
改行の数(Positions.Count)から1つ少ない数まで
1ずつ増分
※1つ少ない数にしている理由は次で説明します
という繰り返し方を設定しました!
ここからは繰り返し処理の中身
Loop ~ End の間の処理を作っていきます!
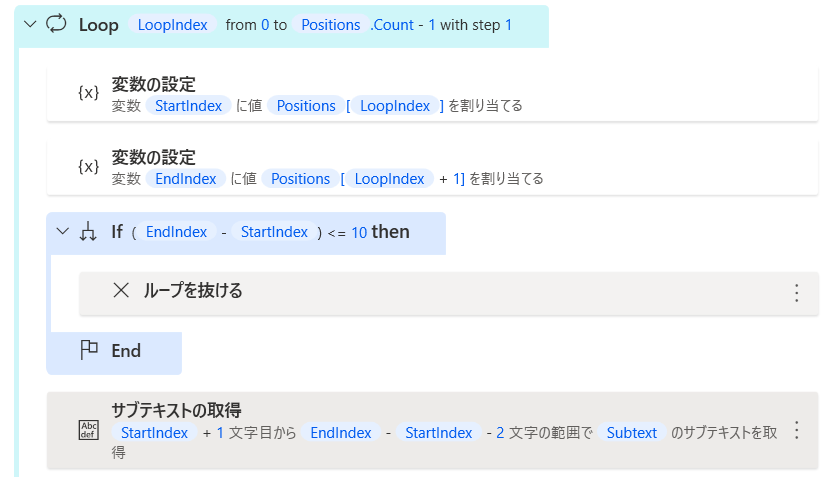
【2】1行分を抜き出す
ここで「Positions」(全ての改行位置)と
「Subtext」(抜き出した文字列)の関係を見直す!
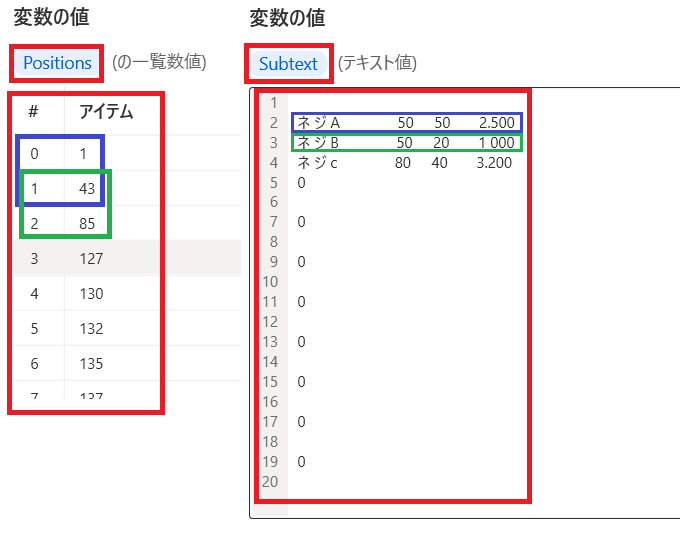
青枠に注目してみると
Positionsの0番目の値「1」と1番目の値「43」
これはSubtextの青枠前後の文字位置を表している!
緑枠も同様である!
では1行分の開始位置と終了位置を変数に格納しましょう!

開始位置を「StartIndex」
終了位置を「EndIndex」として画像の様に定義しました!
※繰り返し回数を「Positions.Count-1」としたのは
「Positions」の最後の要素まで行ってしまうと
「EndIndex」にてPositionsの存在しない次の要素(LoopIndex + 1)を指定してしまうため
また1行分として抜き出したいのは
「ネジA …」「ネジB…」と書いてる行だけなので
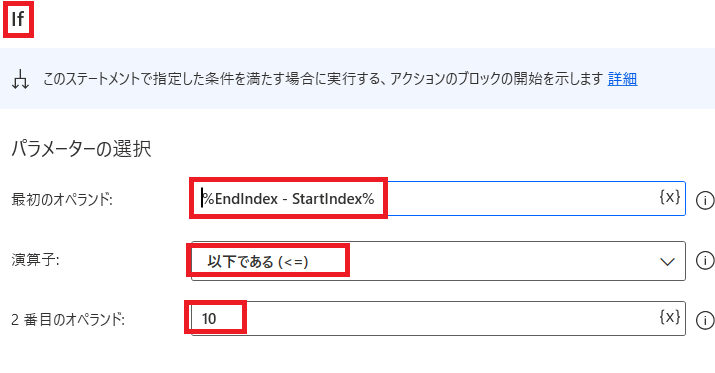
1行分を抜き出す前に
文字数(EndIndex – StartIndex)が10文字以下の場合は
「繰り返し処理を抜ける」と入れておきます!
では「サブテキストの取得」で1行分を抜き出します!
1行分取り出したテキストは
「Data」という変数に格納されます!
※ネジCの行を取得したときのDataの中身

※今のところ繰り返し処理のフローはこんな感じ
【3】1行分のデータをJson形式に整理
「ネジC 80 40 3200」を
{"Row":["ネジC","80","40","3200"]}という形に整理していきます!
※Json形式:{ 名前: 値 }という形
今回は1行分のデータに対してRowと名前を付けている
まず抜き出した1行分のデータを
カンマ区切り&「”」囲み で整理します!
例)「ネジC 80 40 3200」→「”ネジC”,”80″,”40″,”3200″」
今回は
半角スペースが2つ以上ある部分を「”,”」に置換すれば
うまくいきそうなので
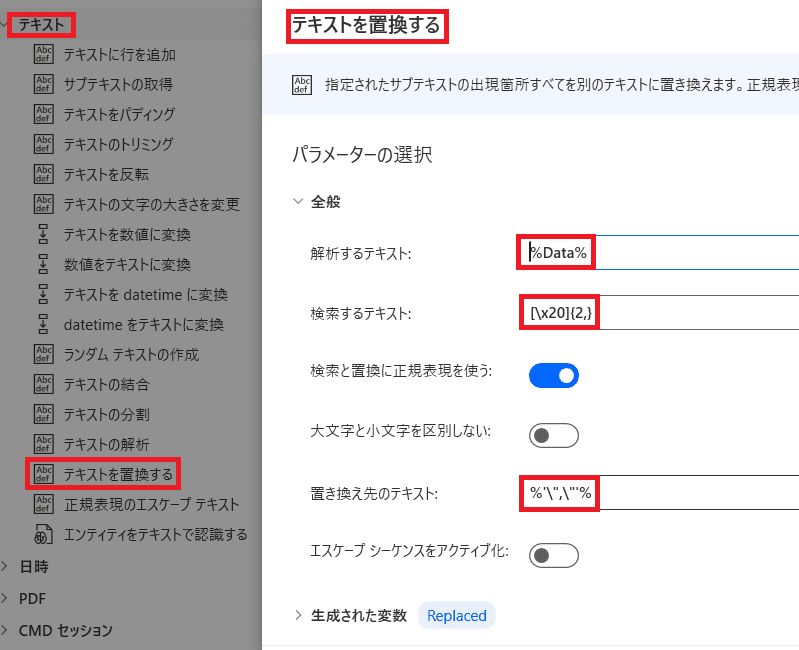
「テキスト」から「テキスト置換」を選ぶ!
検索するテキストは「半角スペースが2つ以上」なので
これを正規表現で表すと
[\x20]{2,}これを「‘,’」で置き換えたいので
置き換え先のテキストはエスケープ文字「\」を使って
%'\",\"'%とりあえずこれで
「Replaced」変数の中身は

最後Json形式になるように
新たに「JsonObject」変数を以下の様に定義します!

そうするとJsonObjectの中身は

という事で1行分のデータを
Json形式に整理できました!
【4】Jsonデータをカスタムオブジェクトに変換
Json形式にしたデータはただの文字列ですが
これをPowerAutomateDesktop内で扱えるオブジェクトに変換します!

「変数」から「JSONをカスタムオブジェクトに変換」を選ぶ!
ここで先ほどJson形式に整理した「JsonObject」をJSON欄に指定!
そうすると変換されたものが「JsonAsCustomObject」変数に格納されます!
変換後の中身をみてみると・・・

「名前」が「Row」で
「値」が「[ ネジC, 80 ,40 , 3200] 」
というデータに変換されてますね!
じゃあ「詳細表示」から
「値」の詳細を見てみると・・・
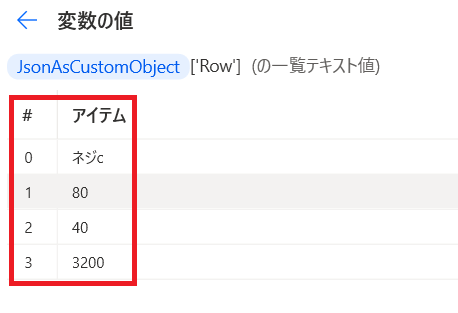
4つのデータが入ったリスト形式のデータになっております!
【5】テーブルにデータを追加
最後にあらかじめ作っておいた
データ追加用のテーブル「DataTable」変数に
リスト形式のデータを追加していきます!

このように
繰り返し処理の中で
テーブルにデータを追加していくと・・・
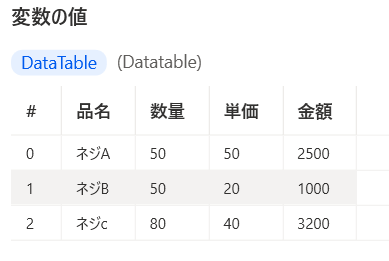
3行4列のテーブルが出来上がりました★
Excel出力
かじむー
Excelを起動
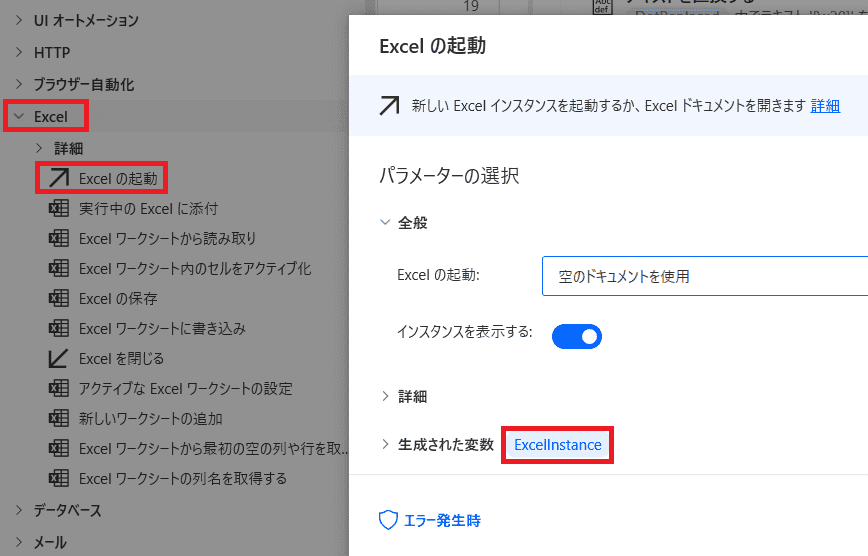
「Excel」から「Excelの起動」を選ぶ!
開かれるExcelオブジェクトが
「ExcelInstance」変数に格納されます!
テーブル化したデータを出力
【1】1行目に列名を出力
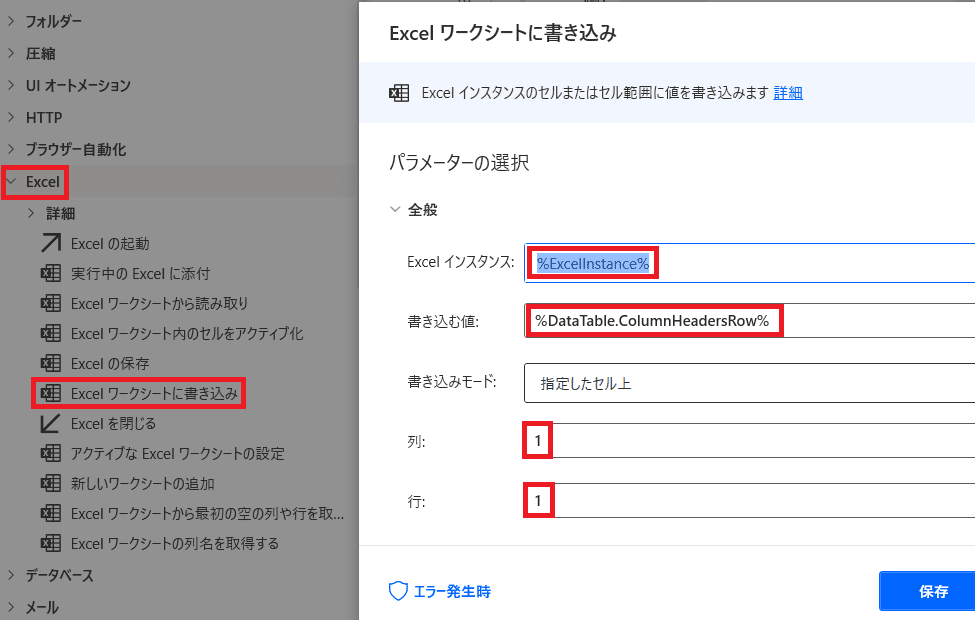
「Excel」から「Excelワークシートに書き込み」を選ぶ!
そして画像の様に値をセットしていきます!
Excelインスタンスには
先ほどのExcelInstance変数を選ぶ!
書き込む値は
「DataTable」の列名を横方向に出したいので
%DataTable.ColumnHeadersRow%と書き表します!
そして列名は1行目に出したいので
出力開始位置は、1列1行目(A1セル)と設定します!
【2】2行目以降にデータを出力
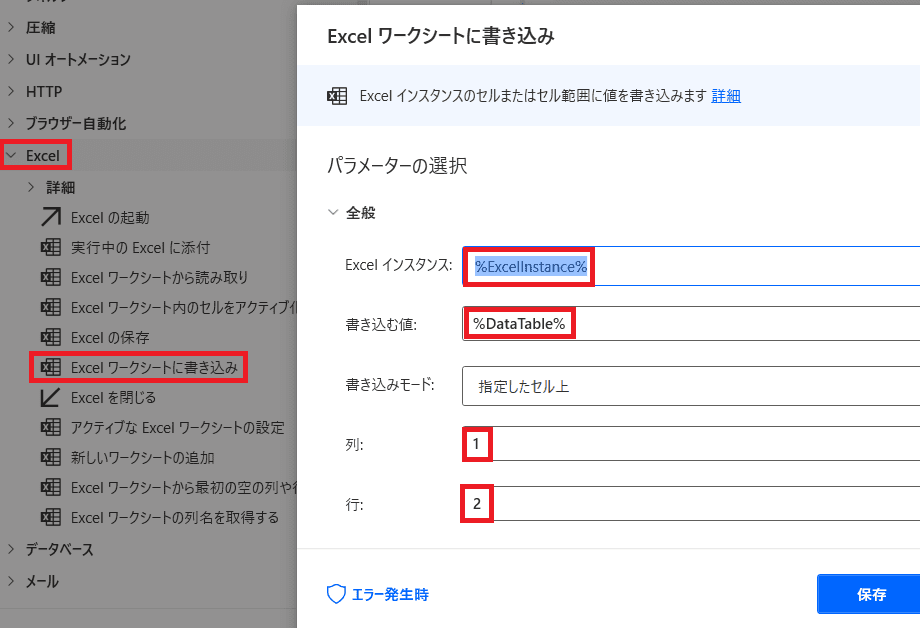
「Excel」から「Excelワークシートに書き込み」を選ぶ!
そして画像の様に値をセットしていきます!
Excelインスタンスには
同様にExcelInstance変数を選ぶ!
書き込む値は「DataTable」を選べば
データのみ書き込まれます!
そしてデータは2行目以降に出したいので
出力開始位置は、1列2行目(A2セル)と設定します!
そうすれば・・・
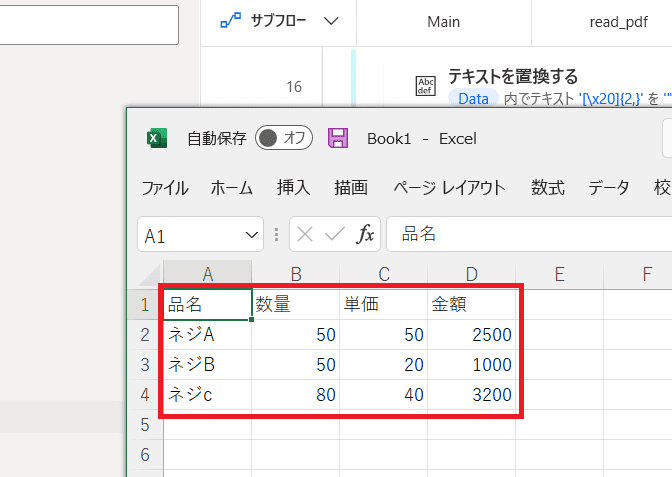
このようにExcelに出力する事が出来ました!
かじむー





