

スレッドの記憶の仕組み
LLMが文章生成する仕組み
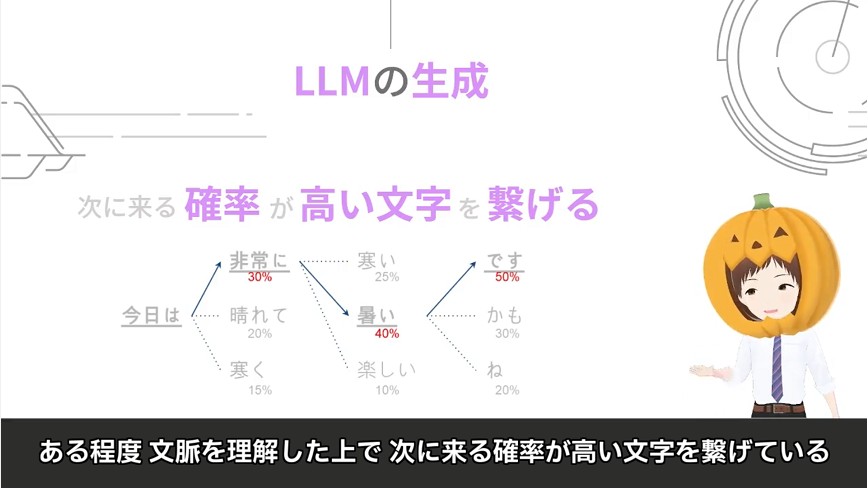
これは前回の記事の復習になりますが
ここが重要になります
LLMというのは
次に来る確率が高い文字をつなげて文章を生成する
これが「記憶」を作っているポイントになります
新規スレッド・過去のスレッドでの結果の違い
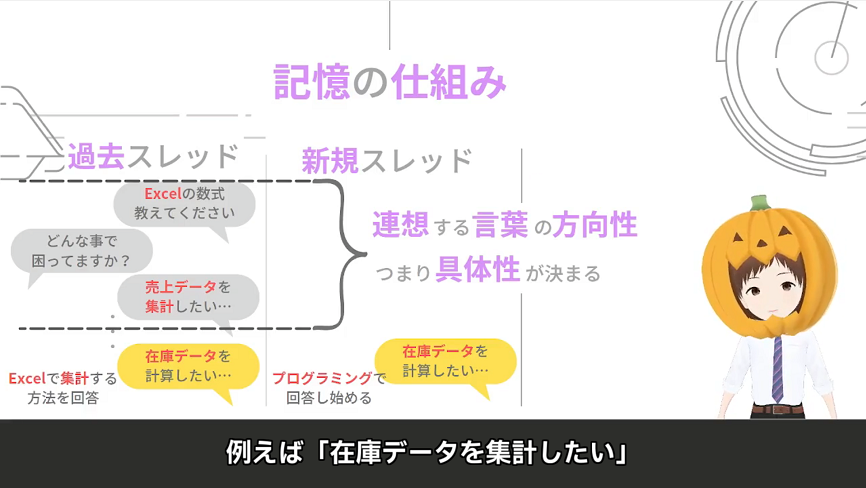
例えば「在庫データを集計したい」
という質問をする場合で考えてみましょう
新規スレッドで質問する場合
新規スレッドで「在庫データを計算したい」というと
多分プログラミングか何かで回答し始めると思います
なぜなら
この質問文に続く文字しか考えられないから
だから手段は勝手に予測され
プログラミングか何かで回答されます
過去スレッドで質問する場合
しかし 例えば 過去に
Excelで集計する方法について
やりとりしていた スレッド が存在していたとします
この続きに「在庫データを計算したい」と質問します
そうすると
過去のやりとり と 質問文 の後に続く
文字の生成をします
過去のやりとりには
“Excel” “集計” などの文字が存在する為
それに続く文字を考えます
だからExcelという手段で回答をし始めるのです
新規スレッドと過去スレッドの使いわけ
つまり
過去スレッドは、新規スレッドよりも
文章を生成する方向性が決まっているんですね
この後に続く文章の方向性
つまり具体性が高まっている 決まっている
という風に言えるんですね
だから 記憶として働く
でも 逆に言うと
過去スレッドは、新規スレッドより
回答が会話履歴に引っ張られる とも言えます
なので そこは分けて使いましょう
引っ張られたくない時は新規スレッド
同じような質問を続けてしたい時は過去のスレッドの続きでやる
こんな風に使い分けていくといいんじゃないかなと思います
最近は Chat GPT に Memory 機能と言って
記憶させたい内容を登録できたりしますので
そこら辺 もうまく使うといいんじゃないかなと思います
では前回の記事から2回にわたって
プロンプトの考え方をお伝えしました
次回は 実際にプロンプトと書く
というところを紹介していきます



