

今回は「生成AIの本質を探る」シリーズ第4回目です。
次のテーマは「文章生成AIのプロンプト」です。
ところでみなさん
プロンプトには
テクニックが必要
だと思っていませんか?
今回は、プロンプト設計の基本的な考え方をお話しします。
皆さん一度は文章生成で納得がいかない結果が出てきた経験あると思います。
それは「相手が何者か」あなたの中で明確になっていないからです。
LLM(大規模言語モデル)とプロンプトの関係を理解し
考え方を一緒に整理しましょう!
LLMとプロンプト
 かじむー
かじむー
LLM(大規模言語モデル)の作り

まずLLMについて情報を整理していきます
これは大規模言語モデルというものになります
このモデルは
大量の文章を学習させて新しい文章を生成できるモデルです
私達はこのモデルに対して会話をしていることになります
じゃどういった文章を学習させてるのか?
- よく知られた一般的な知識が多い
- 英語の内容が多い
一般的な知識というのは
「日本で一番高い山は?」「富士山」といった様な
インターネットで検索すれば出てくるような知識です
また英語の文章を多めに学習させています
しかし最近はOpen AIが日本で
日本語に特化したモデル作りを始めるそうなので
このあたりはまた変化がありそうです
じゃあこのLLM が
どのように文章を生成するのか?
LLMが文章を生成する仕組み
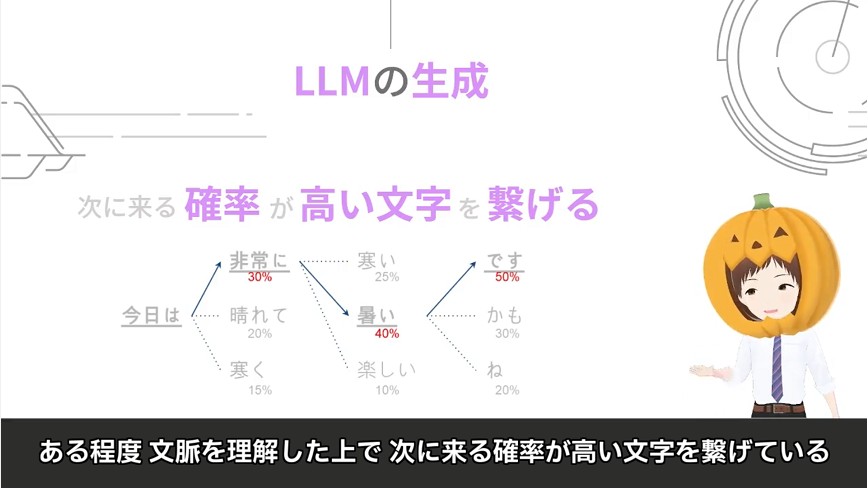
LLMはある程度 文脈を理解した上で
次に来る確率が高い文字を繋げている
どういうことかというと
例えば「今日は」に続く文字として
- 非常に – 30%
- 晴れて – 20%
- 寒く – 10%
上記のように選択肢が3つに絞られ
その中で最も確率が高い「非常に」に決定される
次に「今日は 非常に」に続く文字として
- 寒い – 25%
- 暑い – 40%
- 楽しい – 10%
上記のように選択肢が3つに絞られ
その中で最も確率が高い「暑い」に決定される
こんなイメージです
これを繰り返していく事で
「今日は非常に暑いです」という文字が生成されるのです
文字が少しずつ生成されていくのは こういう事なんだね!
かじむー
一般的なプロンプトのコツ

プロンプトって世間では
細かくて明確な指示をしろ
って言われてるよね
- 条件を与えろ
- 敬語を使え
- 役割を与えろ
- Step By Step は魔法の言葉
じゃあここでそろそろツッコミいれますね
なんでだよ
え?こんなことを 一つ一つ覚えるの?
さっきもLLMってこうだよーとか
プロンプトってこう書くんだよー
は?なんでこんなことを
独立して一つ一つ覚えなきゃいけないの?
ていうか そんなわけないじゃん
何か 本質があるはず
これまでの情報から具体をそぎ落として
抽象化していきます

